- Research
- Open access
- Published:
Application of microservices patterns to big data systems
Journal of Big Data volume 10, Article number: 56 (2023)
Abstract
The panorama of data is ever evolving, and big data has emerged to become one of the most hyped terms in the industry. Today, users are the perpetual producers of data that if gleaned and crunched, have the potential to reveal game-changing patterns. This has introduced an important shift regarding the role of data in organizations and many strive to harness to power of this new material. Howbeit, institutionalizing data is not an easy task and requires the absorption of a great deal of complexity. According to the literature, it is estimated that only 13% of organizations succeeded in delivering on their data strategy. Among the root challenges, big data system development and data architecture are prominent. To this end, this study aims to facilitate data architecture and big data system development by applying well-established patterns of microservices architecture to big data systems. This objective is achieved by two systematic literature reviews, and infusion of results through thematic synthesis. The result of this work is a series of theories that explicates how microservices patterns could be useful for big data systems. These theories are then validated through expert opinion gathering with 7 experts from the industry. The findings emerged from this study indicates that big data architectures can benefit from many principles and patterns of microservices architecture.
Introduction
Today, we live in a world that produces data at an unprecedented rate. The attention toward this large volume of data has been growing rapidly and many strive to harness the advantages of this new resource. This has emerged a new era; the era of big data (BD). The BD era emerged when the velocity, variety, and volume of data overwhelmed existing system capability and capacity to effectively and efficiently process and store data. BD analytics can be described as the practice of crunching large sets of heterogenous data to discover patterns and insights for business competitive advantage.
Academics and practitioners have considered means through which they can incorporate data-driven functions and explore patterns that were otherwise unknown. While the opportunities exist with BD, there are many failed attempts. According to a New Vantage Partners report in 2022, only 26.5% of companies successfully became data-driven [1]. Another survey by Databricks highlighted that only 13% of organizations succeeded in delivering on their data strategy [2].
Therefore, there is an increasing need for more research on reducing the complexity involved with BD projects. One area with good potential is data architecture. Data architecture allows for a flexible and scalable BD system that can account for emerging requirements. One way to absorb the body of knowledge available on data architecture, can be reference architectures (RAs). By presenting proven ways to solve common implementation challenges on an architectural level, RAs support the development of new systems by offering guidance and orientation.
Another concept that has the potential to help with the development of BD systems is the use of microservices (MS) architecture [3]. MS architecture allows for division of complex applications into small, independent, and highly scalable parts and, therefore, increase maintainability and allows for a more flexible implementation [4]. Nevertheless, design and development of MS is sophisticated, since heterogenous services have to interact with each other to achieve the overall goal of the system. One way to reduce that complexity is the use of patterns. Comparable to RAs, they are proven artifacts on how certain problems could be solved. In the realm of MS, there are numerous patters that can be utilized, depending on the desired properties of the developed system. Despite the potential of MS architectures to solve some of complexities of BD development, to our knowledge, there is no study that properly bridges these two concepts.
To this end, this study aims to explore the application of MS patterns to BD systems, in aspiration to solve some of the complexities of BD system development. For this purpose, the result of two distinct systematic literature reviews (SLRs) are combined. The first SLR is conducted as part of this study to collect all MS patterns in the body of knowledge. The second SLR is done by [5] to find all BD reference architectures (RAs) available in the body of knowledge and to point out architectural constructs and limitations. Findings from these SLRs are collected, captured and combined through thematic synthesis. As a result, various design theories are generated and validated through expert opinion gathering.
The contribution of this study, is thereby twofold: (1) it assembles an overview of relevant MS patterns and (2) it creates a connection between BD systems and microservices architecture to facilitate BD system development and data architecture.
Related work
To the best of our knowledge, there is no study in academia that has shared the same goal as our study. Laigner et al. [6] applied an action research and reported on their experience of replacing a legacy BD system with a MS based event-driven system. This study is not a systematic review and aims to create contextualized theory in a controlled environment. In another effort, Zhelev et al. [7] described why event-driven architectures could be a good alternative to monolithic architectures. This study does not follow any clear methodology, and seems to contribute only in terms of untested theory.
Staegemann et al. [8] examined the interplay between BD and MS by conducting a bibliometric review. This study aims to provide a general picture of the topic, and does not aim to explore MS patterns and their relationship to BD systems in detail. Further, Shakir et al. [9] generally discussed how to build BD architectures using MS but didn’t have the same focus on MS patterns we strive for, and Freymann et al. [3] proposed a MS based BD architecture that, however, also didn’t touch on the pattern aspect. While the problem of BD system development has been approached through RAs that absorbs some of the concepts from MS architectures as seen in Phi [10] and Neomycelia [11], there is no study that aimed to apply MS patterns to BD systems through a systematic methodology.
Methodology
Since the goal of this study is to map BD architectures and MS patterns, it is consequently essential to get a comprehensive overview over both domains. For this purpose, it was decided to conduct two systematic literature reviews (SLR), one for each domain. Both SLRs are conducted following the guidelines presented in Kitchenham et al. [12] on evidence-based software engineering and Page et al. [13] on Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA). The former was used because of its clear instructions on critically appraising evidence for validity, impact and applicability in software engineering and the latter was used because it is a comprehensive and well-established methodology for increasing systematicity, transparency, and prevention of bias. To synthesize our findings, thematic synthesis as proposed by Cruzes and Dyba was applied [14].
First review
The first SLR, which focuses on MS patterns, is designed rigorously and is conducted in the following 14 steps: (1) selecting data sources, (2) developing a search strategy, (3) developing inclusion and exclusion criteria, (4) developing the quality framework, (5) pooling literature based on the search strategy, (6) removing duplicates, (7) scanning studies’ titles based on inclusion and exclusion criteria, (8) removing studies based on publication types, (9) scanning studies abstract and title based on inclusion and exclusion criteria, (10) assessing studies based on the quality framework (includes three phases), (11) extracting data from the remaining papers, (12) coding the extracted data, (13) creating themes out of codes, (14) presenting the results. These steps are not direct mappings to the following sub sections. Some sub sections include several of these steps.
Selecting data sources
To assure the comprehensiveness of the review, a broad set of scientific search engines and databases was queried. To increase the likelihood of finding all relevant contributions, it was decided to not discriminate between meta databases and publisher bound registers. Thus, both types were utilized. To achieve this, ACM Digital Library, AISeL, IEEE Xplore, JSTOR, Science Direct, Scopus, Springer Link, and Wiley were included into the search process. For all of these, the initial keyword search was conducted on June 19, 2022, and there was no limitation to the considered publishing date.
Developing a search strategy
Since there are differences in the filters of the included search engines, it was not possible to always use the exact same search terms and settings. Nevertheless, the configurations for the search were kept as similar as possible. The exact keywords and search strategy used can be found at Table 1. These search terms are chosen because patterns are exactly what was sought for, architectures can contain such patterns, and design is often used as a synonym for architecture. Further, patterns can be seen as building blocks, therefore, this term was also included.
Developing inclusion and exclusion criteria
Inspired by the PRISMA checklist [15], our inclusion and exclusion criteria are formulated as following:
Inclusion Criteria: (1) Primary and secondary studies between Jan 1st, 2012 and June 19th, 2022, (2) The focus of the study is on MS patterns, and MS architectural constructs, (3) Scholarly publications such as conference proceedings and journal papers.
Exclusion Criteria: (1) Studies that are not written in English, (2) Informal literature surveys without any clearly defined research questions or research process, (3) Duplicate reports of the same study (a conference and journal version of the same paper). In such cases, the conference paper was removed. (4) Complete duplicates (not just updates) were also removed. (5) Short papers (less than 6 pages not couting the references).
Developing the quality framework
The quality of the evidence collected as a result of this SLR has direct impact on the quality of the findings, making quality assessment an important undertaking. To address this, we developed a quality framework made up of seven aspects. These criteria are informed by the guidelines of Kitchenham [12] on empirical research in software engineering. These seven aspects are discussed in Table 2.
Pooling literature based on the search strategy
Overall, the keyword search yielded 3064 contributions. The total number of found publications per source as well as an overview of the further search process can be seen in Fig. 1.

Overview of the search process
Evaluating papers based on the inclusion and exclusion criteria
In the initial phase, 1196 papers have been removed due to duplication and publication type. The remaining 1868 papers were filtered by title to evaluate their relevance to the concepts of MS patterns or architectural constructs related to MS. For this purpose, the first two authors separately evaluated each entry. If both agreed, this verdict was honored. In case of disagreement, they discussed the title to come to a conclusion. In this phase, the first author initially included 113 papers and the second author 146. Of those, 41 were present in both sets and 1650 were excluded by both. This equates to an agreement rate of 90.5 percent (1691 of 1868 records) between the authors. After discussing the contributions with divergent evaluations, in total, 1699 of the 1868 papers were excluded, leaving 169 items for the next round.
The same approach was followed for abstracts. As a result, the first author evaluated 40 papers positively, and the second one 28. Both agreed on the exclusion of 138. From there on, the papers that were not written in English (despite the abstract being in English), were published before the year 2012, and had a length of less than six pages were removed. 23 papers have been selected for the quality assessment against the quality framework. The agreement rate among researchers for this phase equates to 88 percent.
Evaluating papers based on the quality framework
After having filtered out the pooled studies based on the inclusion and exclusion criteria, we initiated a deeper probing, by running the remaining studies against the quality framework. The filtering based on the quality criteria was divided into three differently focused phases, with each of them requiring the passing of a quality gate as portrayed in Table 2. In the first phase, the aim was to ensure that reports fulfill at least a desired minimum level of comprehensiveness. For this purpose, studies were evaluated for their content to see if they are actual research or just a mere report on some lessons or expert opinions. In addition, we checked if objectives, justification, aim and context of the studies are clearly communicated.
Authors independently rated the three aspects for all 23 remaining papers, giving one point respectively, if they deemed a criterion fulfilled and no point if they considered that aspect lacking. Consequently, for each aspect, zero to two points were achievable and for all aspects, six points were available per paper. For inclusion into the second phase, at least five out of six points were demanded to assure a sufficient base quality. This corresponds to having at least 75 percent of the points. In total, the authors agreed on 51 of 69 evaluations, resulting in an agreement rate of 73,9 percent. The second phase was focused on rigor.
In this phase, studies were judged based on their research design and the data collection methods. The general procedure with the first two authors independently evaluating the reports remained the same. For inclusion in the next phase, again, 75 percent of the obtainable points were needed (this time three out of four). In total, the authors agreed on 23 of 36 evaluations, resulting in an agreement rate of 63.9 percent. While this value is rather low, this is likely caused by the narrow margins for some decisions.
Once more, the papers with the highest score (this time two) were discussed before inclusion, to further counteract possible uncertainty in the individual evaluations. The remaining 10 papers went through the third and final phase. Here, the credibility of the reporting and the relevance of the findings were evaluated. The procedure was the same as the previous phases. However, this time, all of the remaining papers passed. In this last phase, the authors agreed on 14 of 20 evaluations, resulting in an agreement rate of exactly 70 percent.
Forward/backward search
To further increase the comprehensiveness of the review process, following the recommendation of Webster and Watson [16], the initial keyword search was amended with a forward and backward search. Here, for the identified ten papers were examined by which papers they are cited and which papers they cite. This was performed between October 10, 2022 and October 20, 2022. While the backward search could simply be based on the reference lists given in the papers, the forward search was less unequivocal, because there are several sources with slightly varying information. To account for this, two different ones, namely Google Scholar and ResearchGate were used.
However, both searches yielded no new results that sufficed the criteria applied in the initial search. Instead, the 538 papers (combined for all papers and both sources, not accounting for duplicates) found in the forward search comprised, inter alia, thesis works, preprints, studies that are not directly related to microservices, papers that are too short and papers that did not meet the quality criteria. Regarding the backward search, most of the utilized conference papers and journal articles with a focus on microservices were already captured by the initial search, further highlighting its comprehensiveness. In total for the ten papers, and not accounting for duplicates, there were 16 new entries mentioning microservices in the title that were, however, ultimately not relevant for the focus of this work. Therefore, the final set still consists of the ten contributions shown in Table 3.
All ten publications have been published in 2018 or later, with three of them being published in 2022, which shows the timeliness of the topic. Eight of the ten papers were found via Scopus, whereas the remaining two have been identified through IEEE Xplore. The distribution between conference papers and journal articles is equal.
The found papers
To give an overview of the papers found in the literature review and, thereby, also provide context to the extracted knowledge, they are briefly described in the following:
- S1::
-
In [17], the authors conducted a systematic mapping study to identify MS architecture patterns, create a corresponding catalogue that gives an overview of advantages and disadvantages, and, thereby, provide support for developers in finding suitable solutions for their own needs. The initial search for literature yielded 2754 unique papers that were filtered for suitability, resulting in a final set of 42 contributions from conferences, workshops, journals, and grey literature. Besides describing the patterns and outlining in which papers their use has been described, the authors also highlighted the guiding principles of the MS approach in general. Further, corresponding trends and open issues are discussed, amending the given comprehensive overview.
- S2::
-
The use of architectural patterns in open source projects that are based on microservices is addressed in [18]. Similar to the previous one, this article also presents a catalog of microservices architectural patterns based on literature. Further, it relates them to quality attributes, compares them to patterns that are found in service oriented architectures, and investigates which patterns are used in MS-based open source projects. While the general review process seems reasonable, it lacks a reporting of the number of papers assessed in each stage. However, including repeated mentioning across papers, the final set of 16 papers yielded 164 architectural patterns, with 52 stemming from academic papers and 112 from industrial ones. After further processing, those were reduced to 17 patterns that were deemed the most relevant and discussed in more detail.
- S3::
-
A review that is focused on the data management in the context of microservices is presented in [19]. For this purpose, instead of exploring the scientific body of literature, the grey literature was targeted. This is due to the fact that much of the corresponding knowledge on MS architectures can be found in experience reports, blog entries, or system documentations. In total, 35 contributions from practitioners were qualitatively explored analysing which patterns and practices were used by them, and which factors influenced their architectural decisions. Based on the findings, a model was proposed that formalizes the corresponding decisions and thereby facilitates a more comprehensive understanding of the domain.
- S4::
-
The modifiability of software and how it is influenced by the service-oriented architecture (SOA) as well as microservices is examined in [20]. For this purpose, the authors firstly compiled a list of fifteen architectural modifiability tactics and mapped those with eight service-oriented design principles and eight MS principles they extracted from selected publications. Subsequently, they presented the results of the mapping and discussed the results. Further, they analysed the relations of 42 MS and 118 SOA patterns with the modifiability tactics. As with the principles, the patterns were also obtained by consulting specific selected publications. The identified relations are presented and the overall findings discussed, providing the reader with a rather comprehensive insight into the interplay of architectural modifiability, microservices, and SOA.
- S5::
-
A review on the relationship between MS patterns, quality attributes, and metrics is given in [21], which is an updated and extended version of the authors’ previous work. To provide a comprehensive overview, both, scientific literature and grey literature were considered. While initially 605 results were found through the keyword search, the filtering reduced that number to 18. By backward snowballing for the grey literature, this number was increased to 27 for the final set that comprises 13 scientific papers and 14 from grey literature. In total, 54 patterns were identified. However, some of them are strongly related to each other or even redundant. The authors could link the identified patterns to six quality characteristics. Further, they assigned the patterns to one of six groups based on the provided benefits and analysed how many papers from scientific literature and grey literature are related to each group. Moreover, they also provided a comprehensive qualitative discussion of the groups, the respective patterns and the development over time.
- S6::
-
A second literature review on data management in a MS context is presented in [22]. For this purpose, a systematic literature review was conducted, where 300 peer-reviewed papers were analysed, leading to a final selection of 10 articles the authors deemed representative. Further, 9 MS based applications were analysed that were chosen from ‘more than 20’ [22] open-source projects. Additionally, an online survey with more than 120 participants was conducted. In doing so, the authors found out that state-of-the-art database systems are often insufficient for the needs of practitioners, which leads to them combining multiple heterogeneous systems to fulfil their tasks. This, in turn, reduces the importance of database systems when dealing with microservices, since they often only provide data storage functionalities, with the data management logic being shifted to the application layer. Moreover, the data management logic and the common types of queries as well as the major challenges regarding the data management are discussed. Finally, the requirements for database management systems in the context of microservices are highlighted and avenues for future research are outlined.
- S7::
-
MS related deployment and communication patterns were collected in [23]. This was done by conducting a systematic literature review, in which initially 440 items were reviewed, with 34 primary studies being selected as relevant and amended by 4 additional contributions that were found by backward and forward snowballing. Subsequently, the final set is comprehensively presented regarding multiple quality metrics and the applied research methods. In the analysis part, the authors extensively discuss the varying deployment approaches and communication patterns for microservices. Further, they highlight the corresponding obstacles and issues, and promising directions for future research. The work is concluded by a comprehensive overview of its key findings, which are also visualized in the form of a taxonomy.
- S8::
-
The selection of patterns and strategies in MS systems is targeted in [24]. For this purpose, the authors developed and evaluated four decision models that use requirements, in this case desired quality attributes, as input and output appropriate design elements. The models are also the main contribution of this work. Each of the models is focused on one specific theme. These are application decomposition, security, communication, and service discovery. As a foundation for the creation of the models, they searched the existing scientific and grey literature. From an initial set of 2110 publications, they kept 39 scientific papers and 23 grey literature items. Those contained 211 patterns and strategies for the former and 174 for the latter. After duplicate removal, there were 7 patterns and strategies left for application decomposition into microservices, 8 related to security, 15 for microservices communication, and 6 for service discovery. Each of them is briefly summarized and the advantages and disadvantages with respect to the quality attributes is discussed.
- S9::
-
How the use of patterns for the development of MS systems affects the quality is examined in [25]. Further, it is regarded, how and why patterns are adopted in MS systems and how quality attributes in a MS context can be measured. However, at first, the authors introduce and describe the seven quality attributes that are used as foundation for the work. To gather new insights, the authors conducted nine semi-structured face-to-face interviews with practitioners and MS experts. They were questioned regarding the use of the 14 patterns from the “design and implementation” category of the cloud design patterns catalogue [27] provided in the Azure Architecture Center by Microsoft. These are described, the degree of use by the interviewees is stated, and they are linked with the quality attributes. Further, the advantages and disadvantages stated by the interviewees are compared with those that were already present in the documentation of the patterns catalogue.
- S10::
-
The list is concluded by a paper that focuses on a rather broad overview of the MS domain [26]. For this purpose, a systematic literature review, following the PRISMA guidelines [13] was conducted. Hereby, an initial collection of 4056 items was reduced to a final set of 49 papers. The primarily regarded topics are the motivators for the conversion from a monolithic architecture to a MS architecture, which technologies and architectural patterns occur in modern systems and which challenges arise when using the MS architecture. Additionally, future trends are discussed. Here, the increasing importance of cloud computing is highlighted. Other themes are the need to assure a low latency, due to the inherent inter-service communication, as well as the required skill for the development, which could be somewhat counteracted by the development of corresponding tools.
Data synthesis
After selecting the quality papers, we embarked on the data synthesis process. For this phase we follow the guidelines of thematic synthesis discussed by Cruzes et al. [14]. To begin, we first extracted the following data from each paper: (1) findings, (2) research motivation, (3) author, (4) title, (5) research objectives, (6) research method, (7) year. We extracted these data through coding, using the software Nvivo (version 12). After that, we created two codes: (1) patterns, and (2) quality attributes, and coded the findings based on it. By the end of this process, various themes emerged.
Second review
The second SLR is conducted by [5] on available BD RAs in academia and industry. This is a comprehensive study that covers various aspects of BD RAs such as limitations, and common architectural blocks. Therefore, we have foregone to perform an analogous SLR of our own because it would not have yielded new findings. This SLR helped us to determine the requirements that are relevant for BD systems. However, we do not further explore this SLR in this paper, and instead only discuss the results of it. Yet, we recommend to consult it for more details.
Findings
In this section, we present two integral elements: (1) BD requirements, (2) MS patterns.
Requirements specification
The results of our data synthesis emerged a few themes in regards to BD requirements. In order to derive high level requirements for BD systems, we analyzed three sources: (1) system and software requirements for all the RAs found as the result of the second SLR, (2) BD general use cases published in ISO/IEC TR 20547-1:2020 [28], and 3) BD use cases published in [29] and [30]. We created a new Nvivo project and coded every requirement that was found. This resulted in 60 requirements. From there on, we removed duplicate or similar requirements. This process yielded 39 system and software requirements.
After finding these requirements, we sought for a rigorous approach to categorize and represent these requirements. We also did not know what type of requirements would be the most suitable to the goal of this study. To this end, we performed a lightweight literature review in the body of knowledge to realize three major elements: (1) the type of requirements that we need, (2) an approach to categorizing the requirements, (3) presentation of these requirements.
Types of requirements
System and software requirements come in different flavours and can range from a formal (mathematical) specifications to a sketch on a napkin. There have been various attempts to defining and classifying software and system requirements. For the purposes of this study, we opted for a well-received approach discussed by Laplante [31]. In this approach, requirements are classified into three major types of (1) functional requirements, (2) non-functional requirements, and (3) domain requirements. Additionally, we explored the concept of architecturally significant requirements (ASRs) presented by Bass et al. [32].
Our objective is to define the high-level requirements of BD systems, thus we do not fully explore ’non-functional’ and ’domain’ requirements. Majority of non-functional and domain requirements are emerged from the particularities of an environment, such as a banking sector or healthcare, and do not correlate to our study. Therefore, our primary focus is on functional and ASRs. Based on this, we refined the pool of the requirements, which resulted in elimination of 20 entries.
Categorizing requirements
After having filtered out the right type of requirements, we then sought for a rigorous and relevant method to categorize the requirements. For this purpose, we followed the well-established categorization method based on BD characteristics, that is the 5Vs. These 5Vs are volume, velocity, variety, value and veracity [33, 34]. We took inspiration from various studies such as Nadal et al. [35], and the requirements categories presented in NIST BD Public Working Group [36].
The result of the second SLR presented 22 RAs from academia and industry. This study helped us realize the spectrum of BD RAs, how they are designed and the general set of requirements. By analyzing these studies and by evaluating the design and requirement engineering required for BD RAs, we adjusted our initial categories of requirements and added security and privacy to it.
Present requirements
After knowing the type and category of requirements, We looked for a rigorous approach to present these requirements. There are numerous approaches used for software and system requirement representation including informal, semiformal and formal methods. For the purposes of this study, we opted for an informal method because it is a well established method in the industry and academia [37]. Our approach follows the guidelines explained in ISO/IEC/IEEE standard 29148 [38] for representing functional requirements. We have also taken inspiration from the Software Engineering Body of Knowledge [39]. However, our requirement representation is organized in terms of BD characteristics. These requirements are described in following sub sections.
Volume Volume refers to addressing a multitude of data for the purposes of storage and analysis. An architecture needs to be elastic enough to address volume demands at different rates. Storing and computing large volumes of data with attention to efficiency is a complex process that requires distributed and parallel processing. Therefore, volume requirements are as following:
- Vol-1:
-
System needs to support asynchronous, streaming, and batch processing to collect data from centralized, distributed, and other sources
- Vol-2:
-
System needs to provide a scalable storage for massive data sets
Velocity Velocity refers to the rate at which data flows into system for different analytical requirements. Processing of data to expedite the decision-making process quickly on one hand and handling the variety of data and storing them for batch processing, stream processing or micro-batch processing on other hand bring considerable technical challenges. Therefore, velocity requirements are as following:
- Vel-1:
-
System needs to support slow, bursty, and high-throughput data transmission between data sources
- Vel-2:
-
System needs to stream data to data consumers in a timely manner
- Vel-3:
-
System needs to be able to ingest multiple, continuous, time varying data streams
- Vel-4:
-
System shall support fast search from streaming and processed data with high accuracy and relevancy
- Vel-5:
-
System should be able to process data in real-time or near real-time manner
Variety Variety refers to addressing data in different formats such as structured, unstructured, and semi-structured. Different formats may require different processing techniques, may have different storage requirements, and may be optimized in different ways. Hence, an effective BD architecture can handle various data types and enable the processing and transformation of them in an efficient manner. Therefore, the variety requirements are as following:
- Var-1:
-
System needs to support data in various formats ranging from structured to semi-structured and unstructured data
- Var-2:
-
System needs to support aggregation, standardization, and normalization of data from disparate sources
- Var-3:
-
System shall support adaptations mechanisms for schema evolution
- Var-4:
-
System can provide mechanisms to automatically include new data sources
Value Value refers to addressing the process of knowledge extraction from large datasets. Value is perhaps one of the most challenging aspects of BD architecture as it involves a variety of cross-cutting concerns such as data quality, metadata and data interoperability. Gleaning, crunching and extracting value from data requires an integrated approach of storage and computing. Value requirements are as following:
- Val-1:
-
System needs to be able to handle compute-intensive analytical processing and machine learning techniques
- Val-2:
-
System needs to support two types of analytical processing: batch and streaming
- Val-3:
-
System needs to support different output file formats for different purposes
- Val-4:
-
System needs to support streaming results to the consumers
Veracity Veracity refers to keeping a certain level of quality for data. Data veracity refers to truthfulness and accuracy of data; in simpler terms, it is to ensure that data possess qualities necessary for crunching and analysis. Veracity requirements are as following:
- Ver-1:
-
System needs to support data quality curation including classification, pre-processing, format, reduction, and transformation
- Ver-2:
-
System needs to support data provenance including data life cycle management and long-term preservation
Security and privacy Security and privacy should be some of the top concerns for the design of any effective BD system. An effective architecture should be secure, adopting the best security practices (principles of least privilege) and in the meantime respect regional and global privacy rules. The security and privacy requirements are as following:
- SaP-1:
-
System needs to protect and retain privacy and security of sensitive data
- SaP-2:
-
System needs to have access control, and multi-level, policy-driven authentication on protected data and processing nodes
Microservices patterns
As a result of conducted SLR, our data synthesis yielded 28 MS patterns. These patterns are classified based on their function and the problem they solve. Our categories are inspired by the works of Richardson [4] and can be seen in Table 4. While we elaborate the patterns adopted for BD requirements in detail, the aim of our study is not to explain each MS pattern. These patterns can be found in [40]. Nevertheless, we explain the patterns we utilized in this study. These 10 patterns are as following:
-
(1)
API Gateway
-
(2)
Gateway Offloading
-
(3)
External Configuration Store
-
(4)
Competing Consumers
-
(5)
Circuit Breaker
-
(6)
Log Aggregation
-
(7)
Command and Query Responsibility Segregation (CQRS)
-
(8)
Anti-Corruption Layer
-
(9)
Backend for Frontend (BFF)
-
(10)
Pipes and Filters
For the purposes of this study, we utilize Fowler’s definition [41] of patterns as ‘an idea that has been useful in one practical context and will probably be useful in others’.
Several formats are used in the literature to describe patterns. While there is no single format that is widely accepted, there is a broad agreement on what elements should a pattern description include. In this study we use the pattern description template taken from Buschmann et al.’s work [42].
This pattern description language has several elements that do not relate directly to our study. For instance, we do not aim to provide a code example for each pattern, as that is not in-line with our study. Therefore we omitted the headings ‘forces’, ‘variation’, ‘examples’, ‘resulting context’, ‘related patterns’, ‘known uses’, and ‘example application’. Each pattern is discussed in the following subsections in the order of context, problem, and solution. The starting paragraph of each pattern is the context, followed by the ‘problem’ sub section that aims to illuminate on challenges through interrogatives, followed by the ‘solution’ sub section that discuses a better approach through the corresponding pattern.
API gateway
- Context::
-
Suppose that a company runs a multi-region software as a service (SaaS) practice management system for veterinarians, and is using microservices for different aspects of the system such as financial, medical, client and animal related ones. Different frontend applications need different data to display for various parts of the application. The animal micro-frontend needs the animal data, and financial micro-frontend needs data from several backends such as animal, financial, and client.
- Problem::
-
How does the financial micro-frontend retrieve the data it needs from various backends? Should it make a separate REST request to different APIs and then combine the data to represent what is required? How does this approach evolve? If the financial micro service changes, how does it affect the data composition? How does the financial micro-frontend get the new endpoint? How does the financial micro-frontend authenticate with the financial micro service? Should the configs be hard-coded and changed every now and then? If the financial micro service changes implementation of a certain function, would it break production?
- Solution::
-
The solution to these problems is to have one gateway that resolves different data necessary for various micro-frontends. The API gateway can act as a single entry for all clients, handling version changes, reducing the network requests, and addressing cross-cutting concerns. In addition, API gateway can help with load balancing. The gateway can either proxy/route requests to appropriate services or it can fan out a request to multiple services. Underlying this approach the communication pattern is streamlined and micro-frontends are only required to know about the gateway. An overview of this pattern can be found at Fig. 2.
Fig. 2 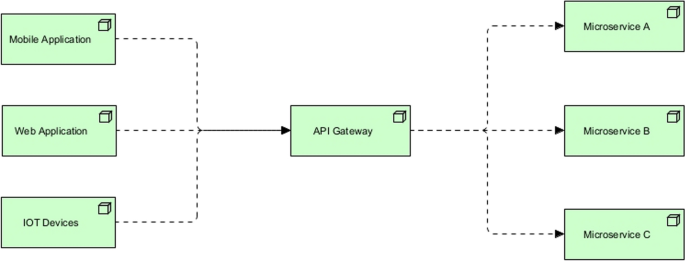
API gateway pattern

Gateway offloading
- Context::
-
Using the same SaaS practice management system example, one can imagine that different microservices have common features and these features require maintenance, configuration and management. The features could be token validation, feature flag management, SSL certificate management, encryption or environment variable management.
- Problem::
-
How does one go about handling these shared features? Should each team write their own feature for their own services? If a feature is updated, should each team then update their own implementation? How do we ensure that these features conform to the same interface and standards? If a new feature is added, should we communicate with three different teams to update their implementation? What happens if an implementation of one team does not respect the specification?
- Solution::
-
Common features and cross-cutting concerns can be offloaded into a gateway. This includes but is not limited to: SSL termination, certificate management, feature flag management, environment variables management, secret management, monitoring, logging configurations, throttling, and protocol translation. This approach simplifies the development of services, and improves the maintainability of the system. In addition, features that require special skills (privacy and security) can be developed by experts and propagated to teams, eliminating the risk that non-expert developers may introduce. This pattern also introduces more consistency, and standardised interfaces, which helps with communication, agility and productivity of development teams. This pattern is portrayed in Fig. 3.
Fig. 3 
Gateway offloading pattern

External configuration store
- Context::
-
Software applications are usually deployed to various environments for different purposes. This is part of the continuous integration, continous delivery (CI/CD) approach that creates pipelines to capture bugs and issues. For instance, there are testing, integration, pre-production, and production environments. Each environment is tailored for a different purpose. In a development environment, several feature flags may be deactivated, some infrastructure may have been configured to reduce costs, and end to end tests may run. Therefore, an application needs to keep a list of configuration for internal and third-party infrastructure it needs. In addition, various classes of services require radically different configurations to meet their ends. These configurations could be a buffer size setup on stream processing services or it could be the timeout time set on batch processing services.
- Problem::
-
Should each application have its configuration written separately? As the number of applications grows, how does one scale and maintain this? If a configuration should be uploaded for a class of similar services, should each service update its configuration separately? How can configurations be shared across several applications?
- Solution::
-
Store all application configurations in an external store. This can include package versions, database credentials, network locations and APIs. On startup, an application can request for the corresponding configuration from the external configuration store. This pattern is portrayed in Fig. 4.
Fig. 4 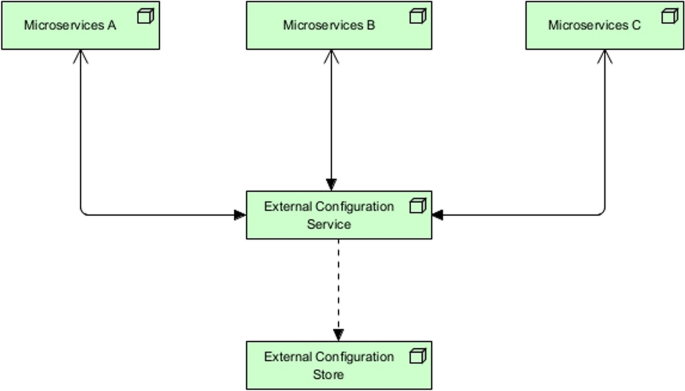
External configuration store pattern

Competing consumers
- Context::
-
An enterprise application, specially a data-intensive one is expected to handle a large number of requests. Handling these requests synchronously would be challenging. A common approach is for applications to send these requests through a messaging system to another application that handles them asynchronously. This ensures that one blocking service is not going to have a ripple effect on the system. Requests loads vary at different times. During peak hours there might be many requests coming from various sources. In addition, the processing required for different requests varies, and while some may be quite cheap, others might be compute intensive.
- Problem::
-
Should only one consumer instance be responsible for incoming requests? What happens if that consumer instance does not have the computing resources available? What happens if that consumer instance fails?
- Solution::
-
A message queue system can be used to load balance requests to different consuming services based on their availability. In this case, a group of consumer applications will be created, which allows for timely processing of incoming requests during peak time. This can be achieved either by a push model (message queue pushing to available consumer nodes), or a pull model (consumer nodes pull requests based on their state and process it).
This increases the elasticity, availability and reliability of the system. The queue can act as a buffer between the producer and consumer instance, and help with minimizing the impact of consumer service’s unavailability. The message can also be enhanced with fault tolerant mechanisms in case of node failures. Furthermore, scalability is improved as new data consumers can be dynamically added. For instance, in AWS, auto scaling groups can be set for EC2 instances. This pattern is presented in Fig. 5.
Fig. 5 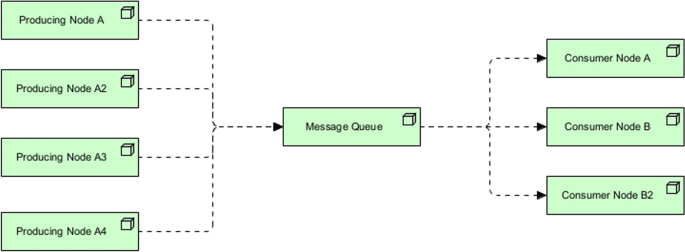
Competing consumers pattern

Circuit breaker
- Context::
-
Suppose a company is using a microservices architecture. There are various services that communicate with each other to process requests. If one service synchronously calls another service through a REST API, there is a chance that the other service may not be available or is exhibiting a high latency. As the number of services grow, there will be an increased requirement for communication between services. Therefore, the failure of one service can introduce a bottleneck to the whole system.
- Problem::
-
How does one handle the failing service? How should the failed service be handled to avoid a ripple effect?
- Solution::
-
An architect can employ the circuit breaker pattern. The circuit breaker pattern prevents services from repeatedly calling the failing service. This allows for the system to operate in spite of a failing node, which helps with saving CPU cycles, improving availability, improving reliability and decreasing the chance of faulty data. In addition, circuit breaker signals the fault resolution, which allows system to get back to its default state.
In a common scenario, circuit breaker acts as a proxy between the source and destination services, and monitors the destination service. If the number of failing requests reaches a certain threshold, the circuit breaker trips, blocking subsequent requests to the destination. The circuit breaker then probes the failing service to identify its health. Once the service becomes healthy again, the circuit breaker allows requests to be passed to the destination.
Circuit breaker can be implemented on frontend, backend, or as a standalone service. This pattern is usually implemented as a state machine that mimics the functionality of an electrical circuit breaker. This is often designed in three states:
-
(1)
Closed: the default state, where the circuit breaker listens on the number of incoming requests
-
(2)
Open: if the number of failing requests reaches a certain threshold, the circuit breaker trips, immediately returning an exception
-
(3)
Half-open: a limited number of requests are passed, if these requests are passed, it is assumed that the service is healthy, and the circuit breaker switches to closed state. If any requests fail, the circuit breaker assumes the fault is still present, so it reverts back to open state
This pattern is displayed in Fig. 6.

Circuit breaker pattern
Log aggregation
- Context::
-
Microservices architectures often comprise a large set of services, each having its own domain and responsibility. A request usually spans multiple services and in the process something might go wrong, and bugs may occur. Each system writes logs in a standardized format about errors, warning and access requests.
- Problem::
-
How to understand the root cause of an issue if it is spanning across multiple services? Should one read the logs of one service, and then the logs of the other and the next to try to make sense of the problem?
- Solution::
-
A centralized logging service can be implemented that retrieves logs from different services and composes them together. The developers can then search and analyze these logs to make sense of the root cause. This eliminates the tedious task of going to each service, extracting logs and aggregating them manually. This pattern is portrayed in Fig. 7.
Fig. 7 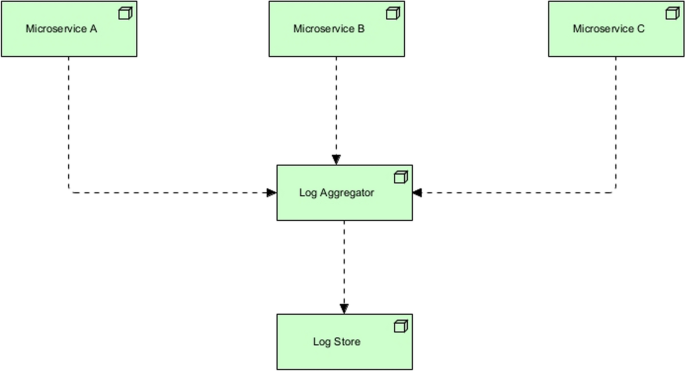
Log aggregation pattern

Command and query responsibility segregation (CQRS)
- Context::
-
Suppose that a team is working on a data heavy service. This service needs to scale and crunch a lot of data. Following the traditional approach, often the same data model is used to query and update the database. Underlying this approach, the read and write workloads both go to the same datastore.
- Problem::
-
How should the team optimize for read workloads? How should the team optimize for the write workloads? Can the team optimize for both read and write workloads? How does the team handle the missmatch between the read and write representations of the data? How does the team ensure a certain performance objective is met on read workloads?
- Solution::
-
Implement CQRS pattern to separate read and write workloads, using commands to update the data and queries to read the data. This is usually achieved through a message queue asynchronously. Having the command and query separated simplifies modeling, development, and maintenance of data stores. In addition, the system will be able to support multiple denormalized views that are optimized for a specific workload.
CQRS is commonly implemented in two distinct data stores. This allows for the read database to optimize for read queries. For instance, it can store a materialized view of the data, and avoid expensive joints or complex ORM mappings. The read database can be a different type of data store. One might choose to use a graph database such as Neo4J for relationship heavy datasets, or a NoSQL database such as MongoDB for highly dynamic data. On the other hand, CQRS can potentially increase complexity, introduce code-duplication and increase latency. An overview of this pattern can be found at Fig. 8.
Fig. 8 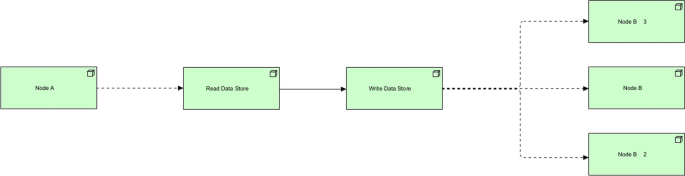
Command and query responsibility segregation pattern

Anti-corruption layer
- Context::
-
Most services rely on some other services for data or functionality. Each service has its own domain model. Some of these services can be external services, some of these services can be internal legacy services, and some of them can be bleeding edge services. For these services to interoperate, there is a need for a standard interface, protocol, data model or APIs.
- Problem::
-
How does one maintain access between legacy internal systems and bleeding edge internal systems? How does one enable interoperability between legacy internal services and external services? Should the bleeding edge service be modified to account for legacy service’s interface or API? Should the internal services support the API requirements of external services even if they are sub-optimal? Should the semantics of legacy and external services be imposed to the bleeding edge service? Should services be corrupted by the requirements of other services?
- Solution::
-
Define an anti-corruption layer that translates semantics between different services’ domains. This enables services to be unaffected by external entities, avoiding compromises on interface, design and the technological approach. The anti-corruption layer can be a module, a class inside the application or it can be an independent service. This pattern is displayed in Fig. 9.

Anti-corruption layer pattern
Backend for frontend
- Context::
-
In a large scale system, a backend service needs to provide the necessary APIs for various clients. A client can be the user’s browser, a mobile phone, or an IoT device. As the number of clients grows, the traffic grows, and new requirements emerge. As a result, the backend service needs to account for higher level of abstraction to serve the requirements of different clients.
- Problem::
-
Should the backend service account for various clients? If the backend service tries to account for all clients, how hard will it be to maintain this service? Can a general-purpose highly abstract backend service be scaled and maintained easily? If the web development team has a conflicting requirement with the mobile development team, how does the backend service account for that? How does the backend service provide optimized data for each client? How can the backend service be optimized for various clients?
- Solution::
-
A dedicated backend that accounts for a specific client (frontend) can be created. This introduces opportunities for optimizing performance of each backend to best match the needs of the frontend, without worrying much about introducing side-effects to other frontends. In addition, the backend will be smaller, better abstracted, less complex, and therefore easier to maintain and scale. Furthermore, this enables horizontal teams to work without side-effects and conflicting requirements. This pattern is depicted in Fig. 10.
Fig. 10 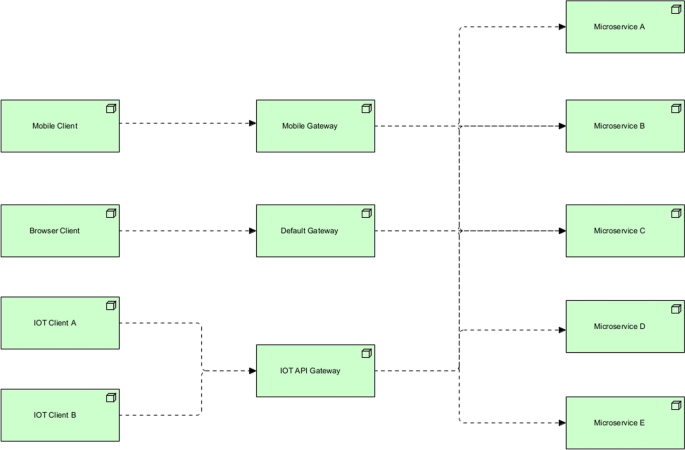
Backend for frontend pattern

Pipes and filters
- Context::
-
A large scale application is usually required to do numerous processes with varying complexity. For instance, a complex business logic may require several transformations to be done on the data. These transformations can be sophisticated and require many lines of code to be written.
- Problem::
-
Should all these processes be performed in one monolithic module? How flexible is that approach? In light of emerging requirements how can one maintain and scale the monolithic module? Is that the right level of abstraction? Does this approach provide with much opportunity to optimize or reuse parts of the module?
- Solution::
-
Different processes can be broken down into their own components (filters), each taking a single responsibility. This provides clean and modular components that can be extended and modified with ease. This pattern is ubiquitous in Unix like operating system; for example it is common for system engineers to pipe the result of the command ‘ls’ (list) into the command ‘grep’ (global search for regular expression) or command ‘sed’ (stream editor). By standardizing the interface for data input and output, these filters can be easily combined to create a more powerful whole. Composition then becomes natural, and the maintainability increases. This pattern is portrated at Fig. 11.
Fig. 11 
Pipes and filters pattern

Application of microservices design patterns to big data systems
In this section, we combine our findings from both SLRs, and present new theories on application of MS design patterns for BD systems. The patterns gleaned are established theories that are derived from actual problems in MS systems in practice, thus we do not aim to re-validate them in this study.
The main contribution of our work is to propose new theories and try to apply some of the well-known software engineering patterns to the realm of data engineering and in specific, BD. Based on this, we map BD system requirements against a pattern and provide reasoning on why such pattern might work for BD systems. We support our arguments by the means of modeling. We use Archimate [43] as recommend in ISO/IEC/IEEE 42010 [44].
We posit that a pattern alone would not be significantly useful to a data engineering or a data architect, and propose that a collection of patterns in relation to current defacto standard of BD architectures is a better means of communication. To achieve this, we portray patterns selected for each requirement in a reference architecture. We then justify the components and describe how patterns could address the requirement. These descriptions are presented as sub sections, each describing one characteristic of BD systems.
Volume
To address the volume requirements of BD, and in specific for Vol-1 and Vol-2 we suggest the following patterns to be effective:
-
(1)
Gateway offloading
-
(2)
API gateway
-
(3)
External Configuration Store
API gateway and gateway offloading
In a typical flow of data engineering, data goes from ingestion, to storage, to transformation and finally to serving. However there are various challenges to achieve this process. One challenge is the realization of various data sources as described in Vol-1. Data comes in various formats from structured to semi-structured to unstructured, and BD systems need to handle different data through different interfaces. There is also streaming data that needs to be handled separately with different architectural constructs and data types. So some of the key engineering considerations for the ingestion process is that; (1) is the BD system ingesting data reliably? How frequently should data be ingested? In what volume the data typically arrive?
Given the challenges and particularities of data types, different nodes may be spawned to handle the volume of data as witnessed in BD RAs studied by Ataei et al. [45]. Another popular approach is the segregation of concerns by separating batch and streaming processing nodes. Given the requirement of horizontal scaling for BD systems, it is safe to assume that there is usually more than one node associated to ingesting data. This can be problematic as different nodes will need to account for security, privacy and regional policies, in addition to the encapsulated data processing functionality.
This means that each node needs to reimplement the same interface for the aforementioned cross-cutting concerns, which makes scalability and maintainability a daunting task. This also introduces unnecessary repetition of codes and can result in non-conforming interfaces. To solve this problem, we explore the concept of gateway offloading pattern. By offloading cross-cutting concerns that are shared across nodes to a single architectural construct, not only will we achieve a separation of concerns and a good level of usability, but we increase security and performance, by processing and filtering incoming data through a well specified ingress controller.
Moreover, if data producers directly communicate with the processing nodes, they will have to update the endpoint address every now and on. This issue is exacerbated when the data producer tries to communicate to a service that is down. Given that lifecycle of a service in a typical distributed cloud environment is not deterministic and many container orchestration systems constantly recycle services to proactively address this issue, reliability and maintainability of the BD system can be compromised. In addition, if all nodes are available externally on several ports, security management can be a daunting task. To solve these issues, the API gateway pattern can be utilized. This pattern provides a single entry for data producers to communicate to internal services. The gateway can then either route incoming requests to responsible services, or it can serve as a proxy.
This layer helps decoupling data producers from the internal services, allowing for better maintainability and scalability of the BD system. In addition, the gateway can increase the system reliability and availability by doing a constant health check on services, and distribute traffic based on liveliness probes. There is also an array of other benefits such as having a weighted distribution, and creating a special cache mechanism through specific HTTP headers. This also means that if the gateway is down, service nodes will not introduce a bad state into the overall system. We have portrayed a simplistic representation of this pattern in Fig 12.

Microservices patterns for BD volume requirements
External configuration store
As discussed earlier, BD systems are made up of various nodes in order to achieve horizontal scalability. While these systems are logically separated to their own service, they will have to communicate with each other in order to achieve the goal of the system. Thus, each one of them will require a set of runtime environmental configuration.
These configurations could be database network locations, feature flags, and third party credentials. Moreover, different stages of the data engineering may have different environments for different purposes, for instance, privacy engineers may require a completely different environment to achieve their requirements. Therefore, the challenge is the management of these configurations as the system scales, and enabling services to run in different environments without modification. To address this problem, we propose the external configuration store pattern.
By externalizing all nodes configurations to another service, each node can request its configuration from an external store on boot up. This can be achieved in Docker files through the CMD command, or could be written in Terraform codes for a Kubernetes pod. This pattern solves the challenges of handling large numbers of nodes in BD systems and provide a scalable solution for handling configurations. This pattern is portrayed in Fig 12.
Velocity
Velocity is perhaps one of the most challenging aspects of BD systems, which if not addressed well, can result in a series of issues from system availability to massive losses and customer churn. To address some of the challenges associated with the velocity aspect of BD systems, we recommend the following patterns for the requirements Vel-1, Vel-2, Vel-3, and Vel-5:
-
(1)
Competing consumers
-
(2)
Circuit breaker
-
(3)
Log aggregation
Competing consumers
BD does not imply only ‘big’ or a lot of data, it also implies the rate at which data can be ingested, stored and analyzed to produce insights. According to a recent MIT report in collaboration with Databricks, one of the main challenges of BD ‘low-achievers’ is the ‘slow processing of large amounts of data’ [2]. If the business desires to go data driven, it should be able to have an acceptable time-to-insight, as critical business decisions cannot wait for data engineering pipelines.
Achieving this in such a distributed setup as BD systems with so many moving parts, is a challenging task, but there are MS patterns that can be tailored to help with some of these challenges. Given the very contrived scenario of a BD system described in the previous section, at the very core, data needs to be ingested quickly, stored in a timely manner, micro-batch, batch, or stream processed, and lastly served to the consumers. So what happens if one node goes down or becomes unavailable? In a traditional Hadoop setup, if Mesos is utilized as the scheduler, the node will be restarted and will go through a lifecycle.
This means during this period of time, the node is unavailable, and any workload for stream processing has to wait, failing to achieve requirements Vel-2, Vel-3 and Vel-5. This issue is exacerbated if the system is designed and architected underlying monolithic pipeline architecture with point-to-point communications. One way to solve some of these issues is to introduce an event driven communication as portrayed in the works of Ataei et al. [11], and try to increase fault tolerance and availability through competing consumers, circuit breaker, and log aggregation.
Underlying the event-driven approach, we can assume that nodes are sending each other events as a means of communication. This implies that node A can send an event to node B in a ‘dispatch and forget’ fashion on a certain topic. However this pattern introduces the same problem as the point-to-point REST communication style; if node B is down, then this will have a ripple effect on the whole system. To address this challenge, we can adopt the competing consumer pattern. Adopting this pattern means instead of one node listening on the topic, there will be a few nodes.
This can change the nature of the communication to asynchronous mode, and allow for better fault tolerance, because if one node is down, the other nodes can listen to the event and handle it. In other terms, because now there are a few consumers listening on the events being dispatched on a certain topic, there is a competition of consumers, therefore the name ‘competing consumers’. For instance, three stream processing consumer nodes can be spawned to listen on data streaming events being dispatched from the the up-stream. This pattern will help alleviate challenges in regards to Vel-2, Vel-3 and Vel-5.
Circuit breaker
On the other hand, given the large number of nodes one can assume for any BD system, one can employ the circuit breaker pattern to signal the service unavailability. Circuit breakers can protect the overall integrity of data and processes by tripping and closing the incoming request to the service. This communicates effectively to the rest of the system that the node is unavailable, allowing engineers to handle such incidents gracefully. This pattern, mixed with competing consumers pattern can increase the overall availability and reliability of the system, and this is achieved by providing an event-driven asynchronous fault tolerance communication mechanisms among BD services. This allows system to be able to be resilient and responsive to bursty, high-throughput data as well as small, batch oriented data, addressing requirements Vel-1, Vel-4, and Vel-5.
Log aggregator
Given that BD systems are comprising of many services, log aggregation can be implemented to shed light on these services and their audit trail. Traditional single node logging does not work very well in distributed environments, as engineers are required to understand the whole flow of data from one end to another. To address this issue, log aggregation can be implemented, which usually comes with a unified interface that services communicates to and log their processes from. This interface then, does the necessary processes on the logs, and finally store the logs.
In addition, reliability engineers can configure alerts to be triggered underlying certain metrics. This increases teams’ agility to proactively resolve issues, which in turn increases reliability and availability, and thereby addresses the velocity requirement of BD systems. While this design pattern does not directly affect any system requirements, it indirectly affects all of them. A simplistic presentation of this pattern is portrayed in Fig 13.

Design patterns for velocity requirements
Variety
Variety, being another important aspect of BD, implies the range of different data types and the challenges of handling the data. As BD systems grow, newer data structures emerge, and an effective BD system must be elastic enough to handle various data types. To address some of the challenges of this endeavour, we recommend the following patterns to address requirements Var-1, Var-3, Var-4:
-
(1)
API gateway
-
(2)
Gateway offloading
API gateway and gateway offloading
We have previously discussed the benefits of API Gateway and Gateway Offloading, however in this section we aim to relate it more to BD system requirements Var-1, Var-3, and Var-4. Data engineers need to keep an open line of communication to data producers on changes that could break the data pipelines and analytics. Suppose that developer A changes a field in a schema of an object that may break a data pipeline or introduce a privacy threat. How can data engineers handle this scenario effectively?
To address this problem, API Gateway and Gateway Offloading can be used. API Gateway and Gateway Offloading could be good patterns to offload some of the light-weight processes that may be associated to the data structure or the type of data. For instance, a light weight metadata check or data scrubbing can be achieved in the gateway. However, gateways themselves should not be taking a lot of responsibility and become a bottleneck to the system. Therefore, as the number of nodes increases and requirements emerge, one might chose to opt for ‘Backend for Frontend’ pattern. We do not do any modeling for this section, as the high-level overview of API Gateway pattern is portrayed in Fig. 12.
Value
Value is the nucleus of any BD endeavour. In fact, all components of the system pursue the goal of realizing a value, that is the insight derived from the data. Howbeit, realizing these insights requires absorption of a great deal of complexity. To address some of these challenges, we propose the following patterns to address the requirements Val-1, Val-3, and Val-4:
-
(1)
CQRS
-
(2)
Anti-corruption layer
Command and Query Responsibility Segregation
Suppose that there are various applications that would like to query data in different ways and with different frequencies (Val-3, Val-4). Different consumers such as business analysts and machine learning engineers have very different demands, and would therefore, create different workloads for the BD systems. As the consumers grow, the application has to handle more object mappings and mutations to meet the consumers’ demands. This may result in complex validation logics, transformations, and serialization that can be write-heavy on the data storage. As a result, the serving layer can end up with an overly complex logic that does too much.
Read and write workloads are really different, and this is something a data engineer should consider from the initial data modeling, to data storage, retrieval and potential serialization. And while the system may be more tolerant on the write side, it may have a requirement to provide reads in a timely manner (checking a fraudulent credit card). Representations of data for reading and writing are frequently mismatched and require a specialized technique and modeling. For instance a snowflake schema may be expensive for writes, but cheap for reads.
To address some of these challenges, we suggest the use of CQRS pattern. This pattern separates the read from writes, using commands to update the data, and query to read data. This implies that the read and write databases can be physically segregated and consistency can be achieved through an event. To keep databases in sync, the write database can publish an event whenever an update occurs, and the read database can listen to it and update its values. This allows for elastic scaling of the read nodes and increased query performance. This also allows for a read optimized data modeling tailored specifically for data consumers. Therefore, this pattern can potentially address the requirement Val-1, and Val-3.
Anti-corruption layer
Another pattern that comes useful when handling large number of data consumers is the anti-corruption layer. Given that the number of consumers and producers can grow and data can be created and requested in different formats with different characteristics, the ingestion and serving layer may be coupled to foreign domains and try to account for an abstraction that aims to encapsulate all the logic in regards to all the external services (data consumers). As the system grows, this abstraction layer becomes harder to maintain, and its maintainability becomes more difficult.
One approach to solve this issue is anti-corruption layer. Anti-corruption layer is a node that can be placed between the serving layer and data consumers or data producer, isolating different systems and translating between domains. This eliminates all the complexity and coupling that could have been otherwise introduced to the ingestion layer or the serving layer. This also allows for nodes to follow the ‘single responsibility’ pattern. Anti-corruption layer can define strong interfaces and quickly serve new demands without affecting much of the serving node’s abstraction. In other terms, it avoids corruption that may happen among systems. This pattern can help with requirements Val-3 and Val-4. We have portrayed this pattern and CQRS in Fig. 14.

Design patterns for value requirement
Veracity
Next to value, veracity is an integral component of any effective BD system. Veracity in general is about how truthful and reliable data is, and how signals can be separated from the noises. Data should conform with the expectations from the business, thus data quality should be engineered across the data lifecycle. According to Eryurek et al. [46], data quality can be defined by three main characteristics (1) accuracy, (2) completeness, and (3) timeliness. Each of these characteristics posits a certain level of challenge to the architecture and engineering of BD systems. Hence, we propose the following patterns for addressing requirements Ver-1, and Ver-4:
-
1.
Pipes and filters
-
2.
Circuit breaker
Pipes and filters
Suppose that there is a data processing node that is responsible for performing a variety of data transformation and other processes with different level of complexities. As requirements emerge, newer approaches of processing may be required, and soon this node will turn into a big monolithic unit that aims to achieve too much. Furthermore, this node is likely to reduce the opportunities of optimization, refactoring, testing and reusing. In addition, as the business requirements emerge, the nature of some of these tasks may be different. Some processes may require a different metadata strategy that requires more computing resources, while others might not require such expensive resources. This is not elastic and can produce unwanted idle times.
One approach to this problem could be the pipes and filters pattern. By implementing pipes and filters, processing required for each stream can be separated into its own node (filter) that performs a single task. This is a well-established approach in unix-like operating systems. Following this approach allows for standardization of the format of the data and processing required for each step. This can help avoiding code duplication and results in easier removal, replacement, augmentation and customization of data processing pipelines, addressing the requirements Ver-1 and Ver-4. This pattern is basically portrayed in all of our models.
Circuit breaker
In an inherently distributed environment like BD, calls to different services may fail due to various issues such as timeouts, transient faults or services being unavailable. While these faults may be transient, this can have a ripple effect on other services in the system, causing a cascading failure across several nodes. This affects system availability and reliability and can cause major losses to the business.
One solution to this problem can be the circuit breaker pattern. Circuit breaker is a pattern that prevents an application from repeatedly trying to access a service that is not available. This improves the fault tolerance among services and signals the service unavailability. The requesting application can decide accordingly on how to handle the situation. In other terms, circuit breakers are like proxies for operations that might fail. This proxy is usually implemented as a state machine having the states close, open, and half-open. Having this proxy in place provides stability to the overall BD system, when the service of interest is recovering from an incident. This can indirectly help with Ver-4. We have portrayed this pattern in Fig. 13.
Security and privacy
Security and privacy should be on top of mind for any BD system development, as these two aspects play an important role in the overall data strategy and architecture of the company. At the intersection of data evolution, regional policies, and company policies, there is a great deal of complexity. To this end, we propose the following pattern to address requirements SaP-1 and SaP-2:
-
1.
Backend for Frontend (BFF)
Backend for frontend
API gateway has been discussed in several sections in this study, however, in this section we are interested to see how it can improve security and privacy of BD systems. In terms of privacy, given the increasing load of data producers, and how they should be directed to the right processing node, how does one comply with regional policies such as GDPR or PCI? How do we ensure, for example, that data is anonymized and identifiable properties are omitted? One approach is to do this right in the API gateway. However as data consumers grow and more data gets in, maintaining the privacy rules and applying them correctly to the dataset in the API gateway becomes more difficult. In addition, this can result in a bloated API gateway with many responsibilities, that can be a potential bottleneck to the system.
One approach to this problem can be the BFF pattern. By creating backends (services) for frontends (data producers), we can logically segregate API gateways for data that requires different level of privacy and security. This logical separation can include other factors such as quality of services (QoS), key accounts, and even the nature of the API (GraphQL or RPC). Implementing this pattern means that instead of trying to account for all privacy related concerns in one node (API gateway), we separate the concerns to a number of nodes that are each responsible for a specific requirement. This means, instead of creating a coupled, loosely abstracted implementation of privacy mechanisms, the system can benefit from hiding sensitive or unnecessary data in a logically separated node. This is also a great opportunity for data mutation, schema validation, and potentially protocol change.
On the other hand, from the security point of view, and in specific in relation to authorization and authentication, this pattern provides with a considerable advantage. BFF can be implemented to achieve token isolation, cookie termination, and a security gate before requests can reach to upstream servers. Other security procedures such as sanitization, data masking, tokenization, and obfuscation can be done in this layer as well. As these BFF servers are logically isolated for specific requirements, maintainability and scalability is increased. This addresses the requirements SaP-1 and SaP-2. We have modeled this pattern in Fig. 15.

Design patterns for security and privacy requirements
Validation
After the generation of the design theories, we sought for a suitable model of validation. This involved a thorough research in some of the well-established methods for validation such as single-case mechanism experiment, technical action research and focus groups [47]. For the purposes of this study we chose export opinion, following the guidelines of Kallio et al. [48].
Research methodology for gathering expert opinion
Our research methodology for gathering expert opinion is made up of four phases: (1) identifying the rationale for gathering expert opinion, (2) formulating the preliminary expert opinion gathering guide, (3) pilot testing the guide, (4) presenting the results.
Expert opinion is suitable for our study, because our conceptual framework is made up of architectural constructs that can benefit from in-depth probing and analysis. As we examine an uncharted territory with a lot of potential, we posit that these expert opinions can post useful leads. These leads can be pursued to further improve the theories of this study.
We’ve formulated our expert opinion guide based on our research objective to achieve the richest possible data. Our guide is flexible, to increase our opportunity to explore new ideas, and allow for participant-orientation. Nevertheless, we formulated some close-ended questions which are good starters, and also help us with some statistics.
Our questions are categorized into main themes and follow-up questions, with main themes being progressive and logical, as recommended by Kallio et al. [48]. We pilot tested our expert opinion guide using internal testing, which involved an evaluation of the preliminary expert opinion guide with the members of the research team. We aimed to assume the role of the expert and gain insight into the limitations of our guide.
This approach helped us capture some issues with the questions, and remove some questions that may be deemed eccentric. Follow-up questions were utilized to direct the dialogue towards the subject of our study, and make things easier for candidates to understand. Some of these follow-up questions were improvised, as we did not aim to rigidly control the flow. After this, to ensure the rigour and relevance of the expert opinion guide, we’ve conducted a pilot test. This step was necessary to make informed adjustments to the guide, and to improve quality of data collection. Our guide is available at Appendix 9.
Sampling strategy
After having our expert opinion guide designed, we used purposive sampling [49] to select experts. We chose purposive sampling because it allowed us to collect rich information by expert sampling. In addition, this approach enabled us to ensure representativeness and removed the need for a sampling frame. We also attempted ‘heterogeneity sampling’ by approaching candidates from various industries.
We reached out to colleagues, our connections on ResearchGate and Linkedin, and tried to look for experts with the titles ’data engineer’, ’data architect’, ’senior data engineer’, ’solution architect’, ’lead architect’, and ’big data architect’. We also included founders of big data companies, or academics who have been working on BD systems. We collected opinions of 7 experts from various industries over a period of 3 months. An overview of these experts is portrayed in Table 5.
Data synthesis
Expert opinions are collected through the software Zoom. We saved all of the recordings, and then downloaded the automatically generated transcripts. Transcripts for each opinion collection session has been added to Nvivo and then codes are created. We created a code for each BD characteristics discussed in section "Requirements specification". Additionally, we added a code named ’comments/suggestions’. After having analyzed all the transcripts, we added a new code named ’limitations’. This last code discussed how some of patterns of microservices may not be relevant at all, or some of the patterns we proposed may introduce challenges.
After the initial coding process, through axial coding, we created higher level codes. These higher level codes were subsequently connected to create themes.
Results
From the results of the export opinion collection, we gathered a lot of insights and probed deep into our architectural constructs. Every session involved an analysis of the design patterns with one question from the expert trying to understand the problem space and the solution proposed. Our experts had at least 8 years of experience. While some had more experience with BD and AI, some others were well-versed in MS architecture. We first asked experts about their depth of understanding with MS and BD, and then asked them if patterns discussed for each characteristic makes sense. We asked every expert if they can think of a pattern that we failed to consider. While we designed the opinion gathering process to be only an hour, the sessions has always exceeded this time. We present the results in sub-section each associated to the corresponding BD characteristic.
Volume
For volume, we went through the theories elaborated in section "Volume". This was accompanied by the model created, and sometimes even live modeling to help with understanding. All of the experts took the idea of API gateway and gateway offloading naturally, while we had to explore the ’external configuration store’ a bit deeper. We used the idea of Kubernetes ingress to help with elaboration of API gateway. We used AWS load balancer example, and discussed the challenges of maintaining certificates and authentication. For the externalized configuration pattern we had to go a bit deeper and talk about a scenario in a which the developer of the batch processing node or the stream processing node, may need to account for the development, trial and production workloads that have different DNS requirements, and configurations. We discussed how environment variables may vary, have trial environments may not need as much resources as the production, how ingress may vary, how recursive DNS resolution would be different, and how buffers, and Infrastructure may vary.
After explaining a scenario, experts agreed that this pattern can help with some of the challenges of data engineering. One expert mentioned that this can even be utilized for special privacy requirements. That is, different nodes may have different configuration based on the privacy policies needed. In addition, there’s been discussion in regards to regional privacy and security requirements and how configuration can help derive them. Some experts discussed that this is a general pattern that any system can utilize to its benefit.
API Gateway and Gateway offloading patterns are often practiced in the industry. Nevertheless, the externalized configuration store is not as well understood. |
In one session, an expert discussed how the description of these patterns and the implementations varied in his professional experience in different companies. He added that most developers tend to have a shallow understanding of why certain pattern is adopted, and thus the implementation usually varies. In addition, the expert stated that once a pattern is implemented, then the challenge is to keep the pattern comply with its intended responsibility. In his experience, many of the patterns such as API gateway suddenly turn into an overarching solution that aims to solve many problems. Thus, patterns may firmly establish the problem domain and the solution initially to demarcate boundaries.
The description of a pattern is one thing, the implementation is another. |
Another expert discussed how they are taking extensive measures to embark on a fully event-driven process, and how a lot of things that we theorize and modeled may sound easy to do, but daunting to implement. The expert explained how they are planning to store data in their AWS S3 initially and then having a Lambda function trigger to start the ETL process. The expert then explained how they need to obtain different configurations from different data providers, and how that can affect the data prepared for data consumers. Furthermore, he added how externalized configuration pattern could be implemented with DynamoDB and Lambda functions.
One of the experts from insurance and finance sector mentioned that scaling the gateway and corresponding nodes may not be as easy as it seems. He mentioned that during normal days there are hardly any claims, and while there’s a special event, the storm comes. The expert mentioned that scaling forecast is usually based on historical data. Further, he mentioned that even the delay in auto-scaling groups in AWS can be problematic for them.
Interviewee i5 from insurance and finance sector mentioned that scaling the gateway and corresponding nodes may not be as easy as it seems. He mentioned that during normal days there are hardly any claims, and when there is a special event, the storm comes. The interviewee mentioned that scaling forecasts are usually based on historical data. Further, he mentioned that even the delay in auto-scaling groups in AWS can be problematic for them.
The same expert from the insurance sector discussed how centralizing configuration may sound like a good idea. Howbeit, he added that this approach makes him slightly nervous, because every service is unique in its own, and may require a specific configuration. He added, that as configurations increase, the externalized configuration node can be bloated, taking so much responsibilities. He added that at times, his team had to reconfigure a service at the fly to prevent customer churn, and with this pattern he finds everything more complicated. At last, he added that in a multi-region operating companies, a centralized configuration store can really help with standardization and maintenance.
Centralization of configuration can initially start effective, but as the number of nodes and configurations increases, this component itself can become challenging to maintain. |
Interviewee i6 has affirmed us that gateway offloading and API gateways are pretty common patterns, and he has witnessed it in several major banks. The same candidate metioned that ‘external configuration store’ pattern is sometimes referred to as ‘declarative configuration management’. The candidate then continued to explain how this pattern can be witnessed in Kubernetes clusters through metadata objects, kube-system, and Etcd.
Velocity
For Velocity, we first started by exploring an event-driven data engineering architecture, and then justified the idea of competing consumers. We then explored how competing consumers can fail, and how circuit breaker pattern can help. Finally we explored the idea of logging and how tail logging and distributed tracing can be achieved through it. An expert challenged the idea of competing consumer and stated that a leader election may be a better choice for a distributed setup as such. The expert also mentioned that circuit breakers could be implemented in the competing consumer nodes, but he could see the value of separating it to its own service. Of particular argument was the fact that circuit breaker’s implementation may not be that complicated and a dedicated service for it can increase costs.
The circuit breaker helps with increasing fault tolerance, but it does so by increasing costs. |
In another session, expert asked about the amalgamation technique for the logs, and discussed how dimensionality of the logs can be challenging. We took both feedbacks of ’leader election’ and ’more in-detailed logging approach’ into consideration. We researched deeper into leader election, logging approaches, and distributed tracing. We found leader election a bit hard to justify, as it introduces a single point of failure, can potentially introduce faulty data as there’s only one point of trust, and partial deployments are really hard to apply. We found that benefits of ’leader election’ pattern to be outweighed by the complexity it introduces. In regards to logging, we found various approaches to distributed tracing and log merging, however these were mostly in-detailed micro approaches, which is not in the scope of our study.
In a separate session, the expert discussed how circuit breakers may need to do load balancing as well. We then discussed how circuit breakers could be implemented in data processing nodes themselves, or in a side car. The expert then explained how they’ve created a system that resembles to the log aggregator pattern. The expert elaborated how the system has a graphical interface that captures errors from various ETL jobs.
An expert from the insurance sector discussed how log aggregator might be a good pattern, but it’s not always great to add so many technologies to the stack. Then he added that each system may have a different logging library and interface and aggregating them may need an effective methodology. The expert described that logging is better be approached through several layers of abstraction. He described how it would be useful to have some easy to understand metrics on the surface level. He added there should not be a need for technical skills to read these metrics. Nevertheless, there should be detailed logs abstracted for more technical users.
One of the important aspects of log aggregation is capturing the right log and presenting it effectively. |
Moreover, it was mentioned that only important pieces of information should be collected and presented, as most web servers such as Nginx create so many logs. In an another expert, the candidate brought to light the challenges of time-synchronization in log aggregator pattern. The candidate, who had a background in financial sector, discussed how handling logs from a large amount of services can introduce a challenge of its own. He continued to describe how critical these logs can be during sensitive stream processing tasks, and how data can easily get into petabytes in the banks.
The candidate recommended to design services in a manner that promotes self-awareness. This is to prevent them from breaking silently, which makes debugging and issue resolution take much longer. He added that this ‘awareness’ can be complementary to the log aggregator, as services can reflect and dispatch an event in regards to the root cause of the failure. In addition, the candidate discussed the benefits of dynamically defining the level of logging.
Services should be ‘self-aware’, capable of reflecting on the issue with right error handling mechanisms. |
He illustrated how dynamically setting the level of logging has been really helpful in his personal experience. The candidate then elaborated further on low-level technical details of implemeting OpenTelemtry [50] for different cases and with different levels of logging.
An expert from the telecommunication domain depicted the fact that signaling unavailability through a circuit breaker would not suffice. The candidate continued discussing that even when services are down, data should still be stored to be processed later. The candidate discussed that services to processes the data may fail, and you may even signal the data producers. But that does not mean that data producers will stop sending you data! He continued discussing how data coming from the producers may be perceived as one transaction, and how sometimes there’s no way to stop the data from getting into the system.
Therefore, he suggested that during the failure, the incoming data should be stored somewhere to be processed later. In his experience, without this, things would become really challenging and there might even be a data loss. The candidate believes that data producers are hardly controlled by the data engineering pipelines and therefore, data architects should adopt the approach of ‘zero expectation from data producers’. He then continued discussing how his team has been handling these situations in Kafka, and how partitions have helped with consistency through offsets.
Signaling unavailability of a service does not always mean that data is not sent into the system. Therefore, it is a good practice to store incoming data in case of service unavailability. |
Variety
For variety, we discussed common data types that need support, and how system may use parquet, JSON, or how unstructured data can introduce challenges. By this point, experts had a better grasp of our models and the gateway patterns, thus there wasn’t much questions. An expert suggested the ‘API composition’ pattern and suggested that we may have various services that handle different data types, but the composition of these data may be necessary. The expert suggested that ‘API composition’ can occur at the egress level.
One expert provided details on how painful it has been for his team to onboard new data producers and how that dramatically slowed the project deadline. The expert added that data received from data producers hardly have the standards necessary, as these data are generated by third-party software that they have no control over. He explained how different versions of the same software create different schema and how this can sometimes break the data engineering pipelines. Then, the expert suggested off-loading more compute intensive checks to gateways. We discussed how that could result in a bloated architectural construct and both parties decided that BFF pattern is probably a better suit.
Data quality cannot be ensured from data producers. One should proactively realize and address this issue. |
Another expert from insurance sector discussed how the rate of change is very slow and most things are standard in insurance and finance sectors. For instance, he stated that if Avro is being used as the data format, the industry will be using the same format for the next 5 years. Additionally, the expert explained breaking that changes, specially schema changes are usually avoided. He added that in German insurance companies, almost everything is standard, and introducing any change would require large scale communication with all insurance companies which is an extensive measure.
One of the participants who had an experience with firmware development (i6), depicted the challenges of working with Eletronic Data Interchange (EDI) formats. In his experience, the data format has hardly changed despite the recent technological advancements, and that had introduced significant challenges to his team.
Variety may not be necessarily a challenge for all industries. |
He then explained how gateway offloading could be useful to isolate this data format only to a group of specialized engineers. This meant that newer, less interested engineers could be working on different nodes concurrently without having to worry about introducing side effects to the pipelines. He mentioned that at times, there were very few people available who were well-aware of EDI. He explained how at the very least with the gateways, the data could be stored in a storage for later processing through special headers.
Value
For value, we discussed CQRS and anti-corruption layer. We first began by exploring the challenges of having to optimize for read and write loads. We discussed how it could be essential for the business to provide read queries in a timely manner, and how trying to model for both read and write queries may not be efficient. For instance, we explored snowflake schemas against star schemas, discussed a typical data analysis flow and provided challenges.
An expert discussed how this pattern can be helpful in companies that have adopted domain-driven design, and how each bounded context can decide how the data should be modeled. Some experts shared the same idea that CQRS should only be applied when the needs arise and not proactively. This is due to the fact that implementing and getting CQRS right comes with complexity, and can dramatically increase cost. An expert suggested that CQRS is perhaps unnecessary in many cases and should be utilized only in special cases. The expert also suggested that a reporting database should suffice, and discussed other optimization strategies that could be applied to optimize for read and write without needing to implement CQRS. One example is using different access techniques for reads and writes.
CQRS increases complexity and cost. This pattern is better implemented in light of business requirements and not proactively. |
These expert opinions shed some lights on how complex implementing CQRS can be, and we deduced that this pattern can introduce challenges and should be adopted when the benefits outweigh the challenges. We also received questions about event sourcing and if that could be applied, as CQRS is usually implemented with event sourcing. However, we do not think that event sourcing can scale to account for big data systems, and the challenges of maintaining event logs can introduce risk to modifiability and performance of the overall system.
An expert discussed how they have implemented something similar to CQRS with Elasticsearch. Another expert mentioned how a lot of things are going on in their MySQL databases, and how during write-heavy times, database is locked and unresponsive. He added how waiting for database to become available has been a pain point, and how their services have timed out on this. The expert explained how the stochastic nature of database locks, made it hard for them to predict and tackle this issue. This expert found the idea behind CQRS relevant and effective in solving some of their problems.
Another expert discussed how they have successfully deployed CQRS into production and how it’s been really effective for them. For instance, the expert discussed that Avro data format has been utilized for the write data store and how without this approach the cost of operation and infrastructure would have been doubled. He added that only a part of complexity is associated to bringing data to the platform and storing it in the write database. He discussed that different data consumers have different use cases, and not everyone would appreciate Parquet data format. He stated that some consumers are more interested in row-based data formats and need more aggregation.
Along the same lines, the expert depicted the fact that human side of things is just as complicated as the technical side. For instance, he gave us several examples in which the data consumer did not know what’s really the most optimized format for his/her workload. This is due to the fact that some consumers are not technical stakeholders, and need to be accounted for. The expert continued describing how his team has to sometimes go to the data consumer directly and understand the usage patterns or algorithms run on the data. From there on, his team then would decide the best data format. Nevertheless, as stakeholders change and requirements emerge, there might be a need for doing this several times, which introduces constant challenge to data engineers.
Data consumers’ requirements are not always clear. Data engineering pipelines should be flexible enough to account for emerging requirements. |
Another interesting fact we learnt was that in the financial and insurance sectors, it is not that unlikely for people to press a button on Friday and come back to get their data on Monday. He added that there are various Fortran and legacy Java applications that are widely used in practice and are really un-optimized.
In another session, the expert discussed the known issues for not applying CQRS to big data systems. The main argument was around the management of overall data volume and the stress that CQRS can introduce to storage media. The expert discussed how CQRS is challenging even in non data-intensive systems, and how BD can exacerbate the challenge. In addition, as discussed by the expert, the network and OS overheads introduced by CQRS and microservices in general may not perform well in BD systems. This issues is discussed in [51].
A candidate from the telecommunication domain (i7) discussed his concerns for CQRS and specifically how two data storages seems really expensive to him. He added that CQRS can stress the data engineering process in terms of storage and backup, because now instead of one database, you have to account for two. He related this to his company and mentioned that a request for such facility can get denied by the accounting department, because it is hard to justify. The candidate believed that this pattern is only useful for fully data-driven large-scale companies that have got significant resources available to then. From his prism, the cost outweights the benefit, and many small to medium sized businesses would not be able to afford this.
Microservices and CQRS pattern increase network and OS overheads. Therefore, architectural tradeoffs should be analyzed before incorporating microservices patterns into big data systems. |
Furthermore, we explained the anti-corruption layer. We discussed how the consumer needs can emerge, and how coupling it all to the read service can affect the system modifiability negatively. This pattern was well-perceived by experts, however there were concerns about the anti-corruption layer itself getting bloated and introducing ’corruption’! However a system architect can tackle this by introducing several anti-corruption layers, or egress nodes that are each responsible for a class of data consumers.
An expert raised the concern that defining the scope of anti-corruption layer may be a challenge. In his experience, data scientists need ‘all the data’ available in the company, and that’s been a challenge for his team in the past. He continued discussing that this pattern can be useful not only from decoupling perspective but from a security and governance point of view. We failed to realize this in our research.
Anti-corruption layer does not only help with abstraction, but it has other positive side-effects such as increased governance and security. |
The expert discussed that at times his team has been asked to provide with a lot of data, and providing it could have cause major security issues. He added that defining these anti-corruption layers with clearly defined contracts between the consumers and the big data system’s canonical data can be an effective measure to govern what should be provided, and is a great opportunity to eliminate security risks.
For security and privacy, we started the discussion by exploring how different companies and regions may have different requirements, and how consuming data from data producers might be affected. We then discussed how having a single gateway to encompass all that logic can be daunting to scale. We then introduced the BFF pattern and elaborated that how each class of data consumers can be associated to a specific BFF. This pattern was well-received. An expert pointed out a potential of the access token pattern to be applied to the BFF. The expert elaborated that how having BFFs can help with cloud design and potential usage of private networks to increase security.
An expert discussed how data engineers are usually not well educated on security matters in his professional experience. He added how expensive it is to train engineers to a good level on security and privacy and even after that the company may not be able to retain them. The expert explained how IT giant companies like Google have the resources necessary to constantly account for emerging privacy and security requirements, while small to medium sized businesses are struggling. Finally he stated that following privacy and security standards is really costly for companies.
During a different session, the participant elaborated on how challenging it would be to have several ingresses into the system, and how BFF pattern may provide some stress on security and platform teams. While he admitted that performance and maintainability may be increase, he found challenges of controlling what comes into the system significant.
The expert added that going BFF requires substantial resources and may not be ideal for every company. From his perspective, BFF was only an unnecessary complexity, stating that his life is gonna be hard if he brought something like this into production.
Many data engineering pipelines benefit from pipes and filters pattern. |
Moreover, an expert discussed how encryption should be taken more seriously in BD world. He admitted that in his experience, most BD architects and data engineers were not in favour of data encryption. This was due to performance issues associated to encryption of large amount of data. The expert then further elaborated on issues that may arise if data is not encrypted. From his perspective, in today’s world there is really no borders with data connectivity and one has to make sure that data is safe. He added that if the architecture depends on the perimeters, you need to make sure these perimeters are concretly defined, he then stated that ‘there are no concretly defined perimeters’!
Filters provide an opportunity for introducing data quality metrics. |
In his view, having access to data storage should not mean having access to data. He suggested hardware encryption to solve some of the performance challenges. The same expert pointed out the challenges of GDPR and privacy. He suggested that ’deleting data’ is as important as storing it, and one should proactively look for opportunities to delete sensitive data.
Security and privacy
For security and privacy, we started the discussion by exploring how different companies and regions may have different requirements, and how consuming data from data producers might be affected. We then discussed how having a single gateway to encompass all that logic can be daunting to scale. We then introduced the BFF pattern and elaborated on how each class of data consumers can be associated to a specific BFF. This pattern was well-received. Interviewee i1 pointed out a potential of the access token pattern to be applied to the BFF. The interviewee elaborated how having BFFs can help with cloud design and potential usage of private networks to increase security.
Interviewee i4 discussed how data engineers are usually not well educated on security matters in his professional experience. He added how expensive it is to train engineers to a good level on security and privacy and even after that the company may not be able to retain them. The interviewee explained how IT giant companies like Google have the resources necessary to constantly account for emerging privacy and security requirements, while small to medium sized businesses are struggling. Finally, he stated that following privacy and security standards is really costly for companies.
In another interview, the participant (i5) elaborated on how challenging it would be to have several ingresses into the system, and how BFF pattern may provide some stress on security and platform teams. While he admitted that performance and maintainability may increase, he perceived the challenge of controlling what comes into the system as significant.
An expert discussed how pipe and filters have been the key for them in production, and how it helped them scale and avoid data corruption. He added that without adopting such pattern, if something broke in a large transformation, you’d never know what went wrong, and you might be forced to rerun a process that takes 5h to complete.
While BFF can be useful in increasing maintainability and scalability of the BD systems, it comes with increased complexity and cost. |
Furthermore, the expert depicted how data quality is becoming more and more important for his team and company. This is due to the fact that the expert works in the insurance sector, and data is used in deciding some of the claims.
The expert admitted that sometimes in the past, many years ago, they had to make difficult decisions because data did not posses the qualities necessary. Moreover, he added that separating transformation into their own service (filters), creates an opportunity for introducing data quality metrics for each transformation, which can be used later to probe what has gone wrong and the team can recover from a corrupted data.
In another session, the participant discussed how circuit breaker should be tied to the end of the data processing and not only to the beginning of it. He elaborated that the server might be healthy when the transformation starts, but that might not be the case when it’s about to end, therefore corrupting the data. Further, he added that this can introduce unnecessary reprocessing.
Other feedbacks, closing thoughts
An examination of the feedback obtained from industry experts has revealed three principal types of patterns:
-
(1)
Patterns that are widely accepted and are already used in practice
-
(2)
Patterns that are applicable, but depending on the context may not be practiced
-
(3)
Patterns that are controversial, and may not suit all projects
An overview of these patterns is portrayed in Table 6.
One of the most experienced interviewees (i1) suggested us to further break down our processing requirements into domains and then utilize gateway aggregation patterns and CQRS to do ‘data as a service’. This idea was driven by data mesh and data fabrics.
Gateway aggregation and CQRS patterns can be utilized to achieve ‘data as a service’. |
One of the most experienced expert suggested us to further break down our processing requirements into domains and then utilize gateway aggregate patterns to do ’data as a service’. This idea was driven by data mesh and data fabrics. All of our experts found the study interesting, and were eager to know more after the opinion collection session.
Another feedback was the idea of having an egress that encapsulate the anti-corruption layer and adds some more into it as well. The pattern ’backend for frontend’ was well received, and our event driven thinking seemed to be very well accepted by the experts. By the result of this expert assessment we realized that we have missed an architectural construct while discussing velocity requirements, which was the message queue. These expert opinions increased our confidence in our results and reasoning and have shed some lights on possible new patterns that we could employ.
We have received a lot of good insights into how else we could model and approach this problem. Some of our experts connected some of the patterns discussed to their own context of practice and helped us realized further improvements. Some patterns like CQRS were challenged more, while some other like pipes and filters have been taken naturally.
Discussion
The results of this study have provided us with two major findings; (1) the progress in the data engineering space seems to be uneven in comparison to software engineering, (2) MS patterns have a great potential for solving some of the BD system development challenges. While data engineering has adopted a few practices from software engineering like DataOps, we posit that more software engineering well-established practices can be absorbed.
Futhermore, majority of the studies that we have analyzed to understand BD systems seem to revolve around crunching and transforming data without much attention to data lifecycle management. This is bold when it comes to addressing major cross-cutting concerns of successful data engineering practice such as security, data quality, DataOps, data architecture, data interoperability, data versioning and testing. In fact, while we found a lot of mature approaches in MS and event driven architectures, we could not find many well-established patterns in the data engineering space. Based on this, we think that data architecture remains a significant challenge and requires more attention from both academia and industry.
The future work from here can be focused on applicability of type 2 patterns discussed in Table 6, and challenging different aspects of type 3 patterns. Moreover, future work can be focused on other categories of patterns that BD systems can benefit from. These can be event-driven patterns, reactive pattern or general intra-module software engineering patterns.
Conclusion
With all the undeniable benefits of BD, the success rate of BD projects is still rare. One of the core challenges of adopting BD lies in data architecture and data engineering. While software engineers have adopted many well-established methods and technologies, data engineering and BD architectures do not seem to benefit a lot from these advancements.
The aim of this study was to explore the relationship and application of MS architecture to BD systems through two distinct SLRs. The results derived from these SLRs presented us with interesting insights on the potential of MS patterns for BD systems. Given the distributed nature of BD systems, MS architectures seems to be a natural fit to solve a myriad of problems that come with decentralization. Even though we created many design theories, modeled patterns against systems, and validated our theories, we believe that our results could be further validated by an empirical study. We, therefore, posit that there is a need for more attention in the area of MS and event-driven architectures in relation to BD systems from both academia and industry.
Availability of data and materials
Not applicable.
References
Davenport TH, Bean R. Davenport TH, Bean R, editors. Big data and AI executive survey 2021. NewVantage Partners; 2022. https://www.newvantage.com/thoughtleadership.
MIT Technology Review Insights. (2021). AI and the future of work: Adopt or be left behind. Retrieved from https://www.databricks.com/resources/whitepaper/mit-technology-review-insights-report.
Freymann A, Maier F, Schaefer K, Böhnel T. Tackling the six fundamental challenges of big data in research projects by utilizing a scalable and modular architecture. In: IoTBDS; 2020. p. 249–256.
Richardson C. Richardson C, editor. A pattern language for microservices. https://microservices.io; 2022. https://microservices.io/patterns/index.html.
Ataei P, Litchfield A. The state of big data reference architectures: a systematic literature review. IEEE Access. 2022;10.
Laigner R, Kalinowski M, Diniz P, Barros L, Cassino C, Lemos M, et al. From a monolithic big data system to a microservices event-driven architecture. In: 2020 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). IEEE; 2020. p. 213–220.
Zhelev S, Rozeva A. Using microservices and event driven architecture for big data stream processing. In: AIP Conference Proceedings. vol. 2172. AIP Publishing LLC; 2019. p. 090010.
Staegemann D, Volk M, Shakir A, Lautenschläger E, Turowski K. Examining the interplay between big data and microservices-a bibliometric review. Complex Syst Inf Model Q. 2021;27(27):87–118.
Shakir A, Staegemann D, Volk M, Jamous N, Turowski K. Towards a concept for building a big data architecture with microservices. In: Business information systems; 2021. p. 83–94.
Maamouri A, Sfaxi L, Robbana R. Phi: A Generic Microservices-Based Big Data Architecture. In: European, Mediterranean, and Middle Eastern Conference on Information Systems. Springer; 2021. p. 3–16.
Ataei P, Litchfield A, NeoMycelia: a software reference architecture for big data systems. In: 2021 28th Asia-Pacific software engineering conference (APSEC). IEEE;2021:452–62.
Kitchenham BA, Dyba T, Jorgensen M. Evidence-based software engineering. In: Proceedings of the 26th international conference on software engineering. IEEE Comput. Soc; 2004. p. 273–281.
Page MJ, Moher D, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. PRISMA 2020 explanation and elaboration: updated guidance and exemplars for reporting systematic reviews. BMJ. 2021;372: n160.
Cruzes DS, Recommended Dyba T, Steps for thematic synthesis in software engineering. In: 2011 International symposium on empirical software engineering and measurement. IEEE; 2011:275–84.
Tricco AC, Lillie E, Zarin W, O’Brien KK, Colquhoun H, Levac D, et al. PRISMA extension for scoping reviews (PRISMA-ScR): checklist and explanation. Ann Intern Med. 2018;169(7):467–73.
Webster J, Watson RT. Analyzing the past to prepare for the future: Writing a literature review. MIS quarterly. 2002;p. xiii–xxiii.
Taibi D, Lenarduzzi V, Pahl C. Architectural patterns for microservices: a systematic mapping study. In: Proceedings of the 8th international conference on cloud computing and services science. SCITEPRESS - Science and Technology Publications; 2018. p. 221–232.
Marquez G, Astudillo H. Actual use of architectural patterns in microservices-based open source projects. In: 2018 25th Asia-Pacific software engineering conference (APSEC). IEEE; 2018:31–40.
Ntentos E, Zdun U, Plakidas K, Schall D, Li F, Meixner S. Supporting architectural decision making on data management in microservice architectures. In: Bures T, Duchien L, Inverardi P, editors. Software Architecture. vol. 11681 of Lecture Notes in Computer Science. Cham: Springer International Publishing; 2019. p. 20–36.
Bogner J, Wagner S, Zimmermann A. Using architectural modifiability tactics to examine evolution qualities of Service- and Microservice-Based Systems: an approach based on principles and patterns. SICS Softw Intensive Cyber Phys Syst. 2019;34(2–3):141–9.
Valdivia JA, Lora-González A, Limón X, Cortes-Verdin K, Ocharán-Hernández JO. Patterns related to microservice architecture: a multivocal literature review. Programm Comput Softw. 2020;46(8):594–608.
Laigner R, Zhou Y, Salles MAV, Liu Y, Kalinowski M. Data management in microservices: state of the practice, challenges, and research directions. Proc VLDB Endow. 2021;14(13):3348–61.
Aksakalli IK, Çelik T, Can AB, Tekinerdogan B. Deployment and communication patterns in microservice architectures: a systematic literature review. J Syst Softw. 2021;180: 111014.
Waseem M, Liang P, Ahmad A, Shahin M, Khan AA, Marquez G. Decision models for selecting patterns and strategies in microservices systems and their evaluation by practitioners. In: 2022 IEEE/ACM 44th international conference on software engineering: software engineering in practice (ICSE-SEIP). IEEE; 2022. p. 135–144.
Vale G, Correia FF, Guerra EM, de Oliveira Rosa T, Fritzsch J, Bogner J. Designing microservice systems using patterns: an empirical study on quality trade-offs. In: 2022 IEEE 19th international conference on software architecture (ICSA). IEEE; 2022. p. 69–79.
Weerasinghe S, Perera I. Taxonomical classification and systematic review on microservices. Int J Eng Trends Technol. 2022;70(3):222–33.
Microsoft. Microsoft, editor. Design and implementation patterns. Microsoft; 2022. Available from: https://learn.microsoft.com/en-us/azure/architecture/patterns/category/design-implementation.
ISO/IEC. (2020). Information technology — Big data reference architecture — Part 1: Framework and application process. ISO/IEC TR 20547-1:2020.
Fox G, Chang W. Big data use cases and requirements. In: 1st Big Data Interoperability Framework Workshop: Building Robust Big Data Ecosystem ISO/IEC JTC. vol. 1; 2014. p. 18–21.
Gölzer P, Cato P, Amberg M. Data processing requirements of industry 4.0-use cases for big data applications. European Conference on Information Systems. 2015.
Laplante PA. Requirements engineering for software and systems. Boca Raton: Auerbach Publications; 2017.
Len Bass RK Dr Paul Clements. Software architecture in practice (SEI series in software engineering) 4th Edition. Addison-Wesley Professional; 4th edition; 2021.
Bughin J. Big data, Big bang? J big Data. 2016;3(1):2.
Rad BB, Ataei P. The big data ecosystem and its environs. Int J Comput Sci Netw Secur. 2017;17(3):38.
Nadal S, Herrero V, Romero O, Abelló A, Franch X, Vansummeren S, et al. A software reference architecture for semantic-aware Big Data systems. Inf Softw Technol. 2017;90:75–92.
Chang WL, Grady N. Chang WL, Grady N, editors. NIST Big Data Interoperability Framework: Volume 1, Definitions. NIST Big Data Public Working Group Definitions and Taxonomies Subgroup; 2019. https://doi.org/10.6028/NIST.SP.1500-1r2.
Kassab M, Neill C, Laplante P. State of practice in requirements engineering: contemporary data. Innov Syst Softw Eng. 2014;10(4):235–41.
ISO/IEC/IEEE. (2018). Systems and software engineering — Life cycle processes — Requirements engineering. ISO/IEC/IEEE 29148:2018.
Abran A, Moore JW, Bourque P, Dupuis R, Tripp L. Software engineering body of knowledge. Angela Burgess: IEEE Computer Society; 2004. p. 25.
Richardson C. Microservices patterns: with examples in Java. New York: Simon and Schuster; 2018.
Fowler M. Analysis patterns: reusable object models. Boston: Addison-Wesley Professional; 1997.
Buschmann F, Meunier R, Rohnert H, Sommerlad P, Stal M. Pattern-oriented software architecture: a system of patterns, vol. 1. Hoboken: Wiley; 2008.
Lankhorst M. A Language for enterprise modelling. In: Enterprise Architecture at Work. Springer; 2013. p. 75–114.
Chaabane M, Bouassida I, Jmaiel M. System of systems software architecture description using the ISO/IEC/IEEE 42010 standard. In: Proceedings of the symposium on applied computing; 2017. p. 1793–1798.
Ataei, P. & Litchfield, A.T. (2020). Big data reference architectures, a systematic literature review.
Eryurek E, Gilad U, Lakshmanan V, Kibunguchy-Grant A, Ashdown J. Data Governance: The Definitive Guide. Sebastopol: OŔeilly Media Inc; 2021.
Wieringa RJ. Design science methodology for information systems and software engineering. Berlin: Springer; 2014.
Kallio H, Pietilä AM, Johnson M, Kangasniemi M. Systematic methodological review: developing a framework for a qualitative semi-structured interview guide. J Adv Nurs. 2016;72(12):2954–65.
Baltes S, Ralph P. Sampling in software engineering research: a critical review and guidelines. Empir Softw Eng. 2022;27(4):1–31.
Chakraborty M, Kundan AP. Architecture of a modern monitoring system. In: Monitoring cloud-native applications. Springer; 2021. p. 55–96.
Sriraman A, Wenisch TF, \(\mu\) suite: a benchmark suite for microservices. In: 2018 IEEE international symposium on workload characterization (IISWC). IEEE;2018:1–12.
Acknowledgements
Not applicable.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
PA has designed the initial research methodology, chose the title and the aim of the paper, and conducted the research with help of DS. PA has taken part in all parts of the paper, and has done the expert opinion collection. DS has contributed to all parts of the research, in specific, the systematic literature review section. DS has written majority of the research methodology section, provided with PRISMA flowcharts, and many reviews. DS helped with focus and direction of the research. DS has also taken part in finding big data experts. Both authors read and approved the final manuscript.
Authors' information
Pouya Ataei received two bachelor’s degree in software engineering from Asia Pacific University, Kuala Lumpure, Malaysia and Staffordshire University, Stoke-On-Trent, The United Kingdom and a master’s degree in software engineering from Staffordshire University, is a current Ph.D. student at Auckland University of Technology, Auckland, New Zealand, working on decentralized and distributed big data architectures. He has been an active researcher in the domain of big data within the past 5 years, having created the Nexus methodology for big data system development, and NeoMycelia, a decentralized software reference architecture for big data systems. His area of interest is in distributed system, in specific event-driven microservices, reactive systems, software architecture, and data engineering.
Daniel Staegemann studied computer science at Technical University Berlin (TUB). He received the master’s degree in 2017. He is currently pursuing the Ph.D. degree with the Otto-von-Guericke University Magdeburg (OVGU), where he has been employed as a scientific researcher since 2018. In this time, he published over 50 research papers, many of these in prestigious outlets such as the Americas Conference on Information Systems (AMCIS), the Pacific Asia Conference on Information Systems (PACIS), the International Conference on Design Science Research in Information Systems and Technology (DESRIST), the International Conference on Business Information Systems (BIS), the Hawaii International Conference on System Sciences (HICSS), and IEEE Access. Besides being an author and speaker at conferences as well as a mini-track and workshop chair, he also regularly acts as a reviewer. His research interest is mainly focused on big data and the corresponding quality assurance, but also encompasses all other related topics.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Expert opinion guide
Introduction
Thanks for your participation. We are collecting your opinion to validate our theories in regards to application of microservices patterns to big data systems. There are no right or wrong answers, and we are really interested in your opinion and experiences. This process should take approximately one hour depending on the flow of our dialogues.
All your responses will be confidential, and the results of this expert opinion gathering will be presented without mentioning your name. You may decline to answer any question or stop the process at any time and for any reason. Should you wish to not answer any of the questions, you may decline the question or stop the process at any time. Are there any questions in regards to what I have just explained ?
Note to the reader/researcher: Please not that this guide aims to only encompass the main themes being discussed with the expert and as such does not include the prompts that may have emerged in the process. Some general prompts and close-ended questions are included.
Establishing rapport
Before we begin, it would be nice if you could introduce yourself and tell me a bit about your background and your area of interest.
Candidates background
-
(1)
Could you please tell me your job title?
-
(2)
Could you please tell me how many years of professional experience have you got in software engineering or data engineering?
Familiarity with big data systems
-
(1)
Could you please tell how many years of experience have you got related to data engineering or big data?
-
(2)
Could you please elaborate on your experience/s with big data systems ( or any related systems )?
Familiarity with microservices
-
1
Could you please tell how many years of experience have you got related to microservices architecture?
-
2
Could you please elaborate on your experience/s with microservices architecture ( or any related systems )?
Microservices patterns for big data systems
-
(1)
How do you find the mapping of the patterns to the mentioned characteristics? ( asked for each characteristic after explaining the theories )
-
(2)
Overall, do you think the concepts discussed could be helpful to practitioners or academics?
-
(3)
Do you see any limitations with our study?
-
(4)
Have we missed any pattern for any problem?
Closing thoughts
-
(1)
Are there any further comments/suggestions/improvements that you have got for our study?
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ataei, P., Staegemann, D. Application of microservices patterns to big data systems. J Big Data 10, 56 (2023). https://doi.org/10.1186/s40537-023-00733-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40537-023-00733-4